워크플로우 파이프라인 시각화, 모니터링



에어플로우 문제점

MWAA

MWAA 장점
빠르게 에어플로우 배포.
빠르고 쉽게 셋업






데모 시나리오
1. S3버킷에 정제되지 않은 원본 데이터가 들어온다
2. Crawler가 데이터를 읽어서 메타테이블을 만든다.
3. 메타테이블을 만든 다음 글루 잡을 실행하여 원본 파일을 읽어서 cleansing 작업과 파케이로 변환. S3(transformed)에 저장한다
4. EMR이 돌아가면서 데이터를 aggregation 해서 group by로 sum을 해서 S3에 저장한다
5. S3에 있는 데이터를 Redshift에 올려서 분석 쿼리를 날린다

Airflow DAG 구성
1. S3 Sensor : S3로 특정 폴더로 떨어지는 파일이 있는지 sensor가 감지하고 workflow를 시작한다
2. Glue Crawler : 정보를 읽어서 메타테이블을 생성
3. Glue ETL Job : Cleansing과 paquet 변환해서 S3에 저장
4. EMR Spark Job :컬럼을 기준으로 group by해서 aggregation. sum을 해서 S3에 저장
5. Copy to Redshift : ETL 작업이 끝난 데이터를 Redshift에 저장

MWAA 실습
S3 버킷 구성

1) DAG폴더에 DAG를 구성하는 파이썬 파일 업로드

2) data폴더에 원본 데이터 업로드


원본 데이터 csv 형식

3) 데이터를 Redshift로 Copy할 때 플러그인으로 카피하도록 zip파일 업로드

4) requirements는 워커에서 파이썬 파일을 실행할 때 필요한 라이브러리를 기술한 파일 업로드

5) scripts 폴더에는 데이터 파이프라인에 사용할 Glue 스크립트, EMR 스크립트 업로드
MWAA 생성


client VPC 설정

실습을 위해 Airflow WEB UI를 퍼블릭으로 설정
웹서버의 보안그룹을 설정

환경의 사양 설정

오토스케일에 적용할 워커, 스케줄러 수 설정

CloudWatch를 통해 로그 기록을 확인할 수 있다
워커 관련 로그와 task 로그를 INFO레벨로 보기

서비스 실행 IAM 권한 - Glue, S3, EMR 권한 설정해놓기

생성 완료

DAG파일을 돌리기 전 작업 세팅
1. 크롤러 생성 - CLI 명령. 메타테이블을 만듦. IAM 콘솔에서 ARN 과 매핑
aws glue create-crawler \
--name airflow-workshop-raw-green-crawler \
--role arn\:aws\:iam::1111111111111111\:role/AWSGlueServiceRoleDefault \
--database-name default \
--targets "{\"S3Targets\":[{\"Path\":\"s3://airflow-yourname-bucket/data/raw/green\"}]}"
2. RedShift 생성 - CLI 명령. DAG에서 redshift 구간에 붙여넣을 IAM ARN 확인
aws glue create-crawler \
--name airflow-workshop-raw-green-crawler \
--role arn\:aws\:iam::1111111111111111\:role/AWSGlueServiceRoleDefault \
--database-name default \
--targets "{\"S3Targets\":[{\"Path\":\"s3://airflow-yourname-bucket/data/raw/green\"}]}"
3. Glue, EMR scripts.zip파일 S3에 업로드

glue-script.py 내용
'''
MIT No Attribution
Copyright <YEAR> <COPYRIGHT HOLDER>
Permission is hereby granted, free of charge, to any person obtaining a copy of this
software and associated documentation files (the "Software"), to deal in the Software
without restriction, including without limitation the rights to use, copy, modify,
merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
'''
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from awsglue.job import Job
from pyspark.context import SparkContext
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME','dag_name','task_id','correlation_id']) # getResolvedOptions 함수를 사용하여 명령줄 인수에서 JOB_NAME, dag_name, task_id, correlation_id와 같은 값을 가져옵니다. 이 값들은 스크립트 실행 시 인수로 전달되어야 합니다.
s3_bucket = "airflow-yourname-bucket" # S3 버킷의 이름을 s3_bucket 변수에 할당합니다. 해당 버킷은 데이터 변환 및 로딩 작업에서 사용될 경로를 지정하는 데 사용됩니다.
sc = SparkContext() # SparkContext를 초기화합니다. Spark 작업을 수행하기 위해 필요한 SparkContext입니다.
glueContext = GlueContext(sc) # GlueContext를 생성합니다. AWS Glue 작업에서 Spark 작업을 실행하기 위한 GlueContext입니다.
spark = glueContext.spark_session # GlueContext를 통해 SparkSession을 가져옵니다. 이 SparkSession은 데이터 변환 작업을 위해 사용됩니다.
job = Job(glueContext) # GlueContext를 사용하여 Job을 생성합니다. 이 Job은 AWS Glue 작업을 관리하고 실행하기 위한 객체입니다.
job.init(args['JOB_NAME'], args) # Job을 초기화합니다. 이때 JOB_NAME과 args를 전달하여 작업을 식별하고 인수를 설정합니다.
logger = glueContext.get_logger()
correlation_id = args['dag_name'] + "." + args['task_id'] + " " + args['correlation_id'] # 작업의 상관 관계 ID를 생성합니다. dag_name, task_id, correlation_id 값을 조합하여 생성됩니다.
logger.info("Correlation ID from GLUE job: " + correlation_id)
## @type: DataSource
## @args: [database = "default", table_name = "green", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
# AWS Glue Data Catalog에서 테이블을 읽어서 동적 프레임(DynamicFrame)을 생성합니다. 이를 통해 데이터를 추출하고 변환할 수 있습니다.
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "default", table_name = "green", transformation_ctx = "datasource0") # crawler의 테이블을 읽어서 dynamic_frame 생성
logger.info("After create_dynamic_frame.from_catalog: " + correlation_id )
## @type: ApplyMapping
## @args: [mapping = [("vendorid", "long", "vendorid", "long"), ("lpep_pickup_datetime", "string", "lpep_pickup_datetime", "string"), ("lpep_dropoff_datetime", "string", "lpep_dropoff_datetime", "string"), ("store_and_fwd_flag", "string", "store_and_fwd_flag", "string"), ("ratecodeid", "long", "ratecodeid", "long"), ("pulocationid", "long", "pulocationid", "long"), ("dolocationid", "long", "dolocationid", "long"), ("passenger_count", "long", "passenger_count", "long"), ("trip_distance", "double", "trip_distance", "double"), ("fare_amount", "double", "fare_amount", "double"), ("extra", "double", "extra", "double"), ("mta_tax", "double", "mta_tax", "double"), ("tip_amount", "double", "tip_amount", "double"), ("tolls_amount", "double", "tolls_amount", "double"), ("ehail_fee", "string", "ehail_fee", "string"), ("improvement_surcharge", "double", "improvement_surcharge", "double"), ("total_amount", "double", "total_amount", "double"), ("payment_type", "long", "payment_type", "long"), ("trip_type", "long", "trip_type", "long")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
# datasource0에 대한 매핑을 적용하여 데이터를 변환합니다. 각 컬럼의 속성을 지정하고, 컬럼 이름을 변경하거나 형식을 변환할 수 있습니다.
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("vendorid", "long", "vendorid", "long"), ("lpep_pickup_datetime", "string", "lpep_pickup_datetime", "string"), ("lpep_dropoff_datetime", "string", "lpep_dropoff_datetime", "string"), ("store_and_fwd_flag", "string", "store_and_fwd_flag", "string"), ("ratecodeid", "long", "ratecodeid", "long"), ("pulocationid", "long", "pulocationid", "long"), ("dolocationid", "long", "dolocationid", "long"), ("passenger_count", "long", "passenger_count", "long"), ("trip_distance", "double", "trip_distance", "double"), ("fare_amount", "double", "fare_amount", "double"), ("extra", "double", "extra", "double"), ("mta_tax", "double", "mta_tax", "double"), ("tip_amount", "double", "tip_amount", "double"), ("tolls_amount", "double", "tolls_amount", "double"), ("ehail_fee", "string", "ehail_fee", "string"), ("improvement_surcharge", "double", "improvement_surcharge", "double"), ("total_amount", "double", "total_amount", "double"), ("payment_type", "long", "payment_type", "long"), ("trip_type", "long", "trip_type", "long")], transformation_ctx = "applymapping1") # 매핑
logger.info("After ApplyMapping: " + correlation_id)
## @type: ResolveChoice
## @args: [choice = "make_struct", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
# applymapping1에서 선택해야 할 다양한 데이터 유형을 해결합니다. 예를 들어, 배열이나 구조체로 데이터를 변환할 수 있습니다.
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_struct", transformation_ctx = "resolvechoice2")
logger.info("After ResolveChoice: " + correlation_id)
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
# resolvechoice2에서 널 값을 가진 레코드를 제거합니다.
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
logger.info("After DropNullFields: " + correlation_id)
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://airflow-yourname-bucket/data/transformed/green"}, format = "parquet", transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
# dropnullfields3에서 변환된 데이터를 지정된 경로에 저장합니다. connection_type을 "s3"로 설정하여 S3에 쓰도록 지정하고, connection_options를 사용하여 저장할 S3 경로를 지정합니다. 여기서는 파케이 형식으로 데이터를 저장합니다.
datasink4 = glueContext.write_dynamic_frame.from_options(frame = dropnullfields3, connection_type = "s3", connection_options = {"path": f"s3://{s3_bucket}/data/transformed/green"}, format = "parquet", transformation_ctx = "datasink4") # crawler의 테이블 값을 S3에 파케이 파일로 변환
logger.info("After write_dynamic_frame.from_options: " + correlation_id)
job.commit() # AWS Glue Job을 커밋하여 작업을 실행합니다. 이를 통해 데이터 변환 및 로딩 작업이 완료됩니다.emr-script.py 내용
'''
MIT No Attribution
Copyright <YEAR> <COPYRIGHT HOLDER>
Permission is hereby granted, free of charge, to any person obtaining a copy of this
software and associated documentation files (the "Software"), to deal in the Software
without restriction, including without limitation the rights to use, copy, modify,
merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
permit persons to whom the Software is furnished to do so.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
'''
from __future__ import print_function
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum
if __name__ == "__main__": # 이 줄은 현재 스크립트가 직접 실행되었는지 확인하는 Python의 관례적인 방법입니다.
if len(sys.argv) != 6: # 명령줄 인수의 개수가 6이 아니면, 사용 방법을 출력하고 -1로 스크립트를 종료합니다.
print("""
Usage: nyc_aggregations.py <s3_input_path> <s3_output_path> <dag_name> <task_id> <correlation_id>
""", file=sys.stderr)
sys.exit(-1)
input_path = sys.argv[1] # 첫 번째 명령줄 인수를 input_path 변수에 할당합니다. 예를 들어, python nyc_aggregations.py s3://input_bucket/data/ s3://output_bucket/result/ my_dag_name my_task_id 12345와 같은 명령을 실행한 경우, input_path는 "s3://input_bucket/data/"가 됩니다.
output_path = sys.argv[2] # 두 번째 명령줄 인수를 output_path 변수에 할당합니다.예를 들어, 위의 명령을 실행한 경우, output_path는 "s3://output_bucket/result/"가 됩니다.
dag_task_name = sys.argv[3] + "." + sys.argv[4] # 세 번째와 네 번째 명령줄 인수를 조합하여 dag_task_name 변수에 할당합니다.예를 들어, 위의 명령을 실행한 경우, dag_task_name은 "my_dag_name.my_task_id"가 됩니다.
correlation_id = dag_task_name + " " + sys.argv[5] # dag_task_name과 다섯 번째 명령줄 인수를 공백으로 구분하여 correlation_id 변수에 할당합니다.예를 들어, 위의 명령을 실행한 경우, correlation_id는 "my_dag_name.my_task_id 12345"가 됩니다.
# 이렇게 코드는 명령줄 인수를 사용하여 입력 경로, 출력 경로, 작업 이름 및 상관 ID와 같은 변수를 초기화합니다. 이후에는 이러한 변수를 사용하여 데이터 처리 또는 분석 작업을 수행할 수 있습니다.
spark = SparkSession\ # spark 세션 생성. builder를 사용하여 SparkSession 객체를 생성하고, appName 메서드를 통해 애플리케이션의 이름을 correlation_id로 지정합니다.
.builder\
.appName(correlation_id)\
.getOrCreate() # getOrCreate 메서드는 이미 존재하는 SparkSession이 있는 경우 해당 세션을 반환하고, 그렇지 않은 경우 새로운 세션을 생성합니다.
sc = spark.sparkContext # spark 객체의 sparkContext 속성을 사용하여 SparkContext를 가져옵니다.SparkContext는 RDD(Resilient Distributed Dataset)를 생성하고 클러스터에 대한 작업을 수행하는 데 사용되는 핵심 개체입니다.
log4jLogger = sc._jvm.org.apache.log4j # sc 객체의 _jvm 속성을 사용하여 Java Virtual Machine(JVM)에 대한 접근을 얻습니다.org.apache.log4j 패키지를 사용하여 Log4j 라이브러리에 대한 접근을 얻습니다.
logger = log4jLogger.LogManager.getLogger(dag_task_name) # log4jLogger 객체를 사용하여 Log4j의 LogManager를 얻고, getLogger 메서드를 호출하여 로깅 객체를 가져옵니다. dag_task_name을 로깅 객체의 이름으로 지정합니다.
logger.info("Spark session started: " + correlation_id) # logger 객체를 사용하여 로그를 기록합니다. "Spark session started: "와 correlation_id를 결합하여 로그 메시지를 생성합니다. info 메서드를 사용하여 로그 메시지를 기록합니다.
# 이렇게 코드는 SparkSession을 생성하고 Spark 로깅 설정을 위한 로깅 로직을 포함합니다. 이를 통해 Spark 애플리케이션의 세션을 초기화하고 로그를 기록할 수 있습니다.
df = spark.read.parquet(input_path) # 파케이 파일 읽기
df.printSchema
df_out = df.groupBy('pulocationid', 'trip_type', 'payment_type').agg(sum('fare_amount').alias('total_fare_amount')) # groupby 그룹화 후 요금을 sum
df_out.write.mode('overwrite').parquet(output_path) # 출력 경로에 wirte
logger.info("Stopping Spark session: " + correlation_id)
spark.stop()// (CLI버전) 파일 업로드
// (CLI버전) 수정된 작업 스크립트를 S3 경로 s3://airflow-yourname-bucket/scripts/glue/ 에 복사합니다 .
// (CLI버전) EMR 작업 스크립트인 nyc_aggregations.py (이전에 Glue ETL 작업 단계에서 다운로드한 여기) 를 복사
unzip scripts.zip
aws s3 sync ./scripts/glue s3://airflow-yourname-bucket/scripts/glue/
aws s3 sync ./scripts/glue s3://airflow-yourname-bucket/scripts/glue/4. Glue 생성 - IAM 콘솔 - 역할 로 이동, AWSGlueServiceRoleDefault을 검색하고 역할 이름을 클릭한 다음 역할 ARN을 복사합니다 .
aws glue create-job \
--name nyc_raw_to_transform \
--role arn\:aws\:iam::1111111111111111\:role/AWSGlueServiceRoleDefault \
--glue-version 3.0 \
--default-arguments TempDir="s3://airflow-yourname-bucket/glue-temp/" \
--command "Name=glueetl,ScriptLocation=s3://airflow-yourname-bucket/scripts/glue/nyc_raw_to_transform.py,PythonVersion=3" \
DAG 파일 작성
from datetime import timedelta
import airflow
from airflow import DAG
from airflow.providers.amazon.aws.sensors.s3_prefix import S3PrefixSensor
from airflow.providers.amazon.aws.operators.emr_create_job_flow import EmrCreateJobFlowOperator
from airflow.providers.amazon.aws.operators.emr_add_steps import EmrAddStepsOperator
from airflow.providers.amazon.aws.operators.emr_terminate_job_flow import EmrTerminateJobFlowOperator
from airflow.providers.amazon.aws.sensors.emr_step import EmrStepSensor
from airflow.providers.amazon.aws.operators.glue import AwsGlueJobOperator
from airflow.providers.amazon.aws.operators.glue_crawler import AwsGlueCrawlerOperator
# Custom Operators deployed as Airflow plugins
from awsairflowlib.operators.aws_copy_s3_to_redshift import CopyS3ToRedshiftOperator
S3_BUCKET_NAME = "airflow-yourname-bucket" # 데이터와 스크립트가 저장될 S3 버킷 이름을 지정
dag_name = "mwaa_data_pipeline"
# Unique identifier for the DAG
correlation_id = "{{ run_id }}"
default_args = { # Airflow DAG에 대한 기본 매개변수 집합을 정의
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(1),
'retries': 0,
'retry_delay': timedelta(minutes=2),
'provide_context': True,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False
}
dag = DAG( # DAG 생성. DAG가 실행되어야 하는 일정 간격을 지정
dag_name,
default_args=default_args,
dagrun_timeout=timedelta(hours=2),
schedule_interval='0 3 * * *'
)
s3_sensor = S3PrefixSensor( # S3에 원본파일이 떨어지는 것을 감지
task_id='s3_sensor',
bucket_name=S3_BUCKET_NAME,
prefix='data/raw/green',
dag=dag
)
################## crawler #######################
config = {"Name": "airflow-workshop-raw-green-crawler"}
glue_crawler = AwsGlueCrawlerOperator( # 크롤러 정의
task_id="glue_crawler",
config=config,
dag=dag)
#Glue 연산자와 후크를 사용하여 DAG 작업을 아래와 같이 작성하여 기존 Glue 작업을 호출할 수 있습니다.
#인수는 글루 작업 스크립트에서 액세스할 연산자를 통해 전달됩니다.
glue_task = AwsGlueJobOperator( # 데이터가 도착하면 크롤러 실행. 메타 테이블이 생성됨
task_id='glue_task',
job_name='nyc_raw_to_transform',
iam_role_name='AWSGlueServiceRoleDefault',
script_args={'--dag_name': dag_name,
'--task_id': 'glue_task',
'--correlation_id': correlation_id},
dag=dag)
########################## EMR ##################
## Override values for task Id 'create_emr_cluster'
JOB_FLOW_OVERRIDES = {
"Name": dag_name + ".create_emr_cluster-" + correlation_id,
"ReleaseLabel": "emr-5.29.0",
"LogUri": "s3://{}/logs/emr/{}/create_emr_cluster/{}".format(S3_BUCKET_NAME, dag_name, correlation_id),
"Instances": {
"InstanceGroups": [
{
"Name": "Leader node",
"Market": "ON_DEMAND",
"InstanceRole": "MASTER",
"InstanceType": "m5.xlarge",
"InstanceCount": 1
},
{
"Name": "Core nodes",
"Market": "ON_DEMAND",
"InstanceRole": "CORE",
"InstanceType": "m5.xlarge",
"InstanceCount": 2
}
],
"TerminationProtected": False,
"KeepJobFlowAliveWhenNoSteps": True
},
"Tags": [
{
"Key": "correlation_id",
"Value": correlation_id
},
{
"Key": "dag_name",
"Value": dag_name
}
]
}
# 다음으로 EMR 클러스터에 제출할 작업 단계를 정의합니다.
S3_URI = "s3://{}/scripts/emr/".format(S3_BUCKET_NAME)
## Steps for task Id 'add_steps'
SPARK_TEST_STEPS = [
{
'Name': 'setup - copy files',
'ActionOnFailure': 'CANCEL_AND_WAIT',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': ['aws', 's3', 'cp', '--recursive', S3_URI, '/home/hadoop/']
}
},
{
'Name': 'Run Spark',
'ActionOnFailure': 'CANCEL_AND_WAIT',
'HadoopJarStep': {
'Jar': 'command-runner.jar',
'Args': ['spark-submit',
'/home/hadoop/nyc_aggregations.py',
's3://{}/data/transformed/green'.format(S3_BUCKET_NAME), # 이 파일을 읽고 aggregation
's3://{}/data/aggregated/green'.format(S3_BUCKET_NAME), # aggregation된 파일을 S3에 저장
dag_name,
'add_steps',
correlation_id]
}
}
]
# EMR 클러스터 및 Spark 작업에 대한 정의를 생성했으면 DAG의 일부가 될 작업을 정의할 시간입니다.
# 첫 번째 작업은 EMR 클러스터를 생성하는 것입니다.
cluster_creator = EmrCreateJobFlowOperator(
task_id='create_emr_cluster',
job_flow_overrides=JOB_FLOW_OVERRIDES,
aws_conn_id='aws_default',
emr_conn_id='emr_default',
dag=dag
)
# 다음으로 클러스터가 생성되면 단계(Spark 작업)를 EMR 클러스터에 제출하는 작업을 생성합니다.
step_adder = EmrAddStepsOperator(
task_id='add_steps',
job_flow_id="{{ task_instance.xcom_pull('create_emr_cluster', key='return_value') }}",
aws_conn_id='aws_default',
steps=SPARK_TEST_STEPS,
dag=dag
)
# 다음으로 클러스터가 생성되면 단계(Spark 작업)를 EMR 클러스터에 제출하는 작업을 생성합니다.
# EMR 스크립트 실행
step_adder = EmrAddStepsOperator(
task_id='add_steps',
job_flow_id="{{ task_instance.xcom_pull('create_emr_cluster', key='return_value') }}",
aws_conn_id='aws_default',
steps=SPARK_TEST_STEPS,
dag=dag
)
# 클러스터를 종료하기 전에 작업이 완료 단계(성공 또는 실패 실행)에 도달할 때까지 기다리기 위해 Watch 작업을 추가해야 합니다.
step_checker1 = EmrStepSensor(
task_id='watch_step1',
job_flow_id="{{ task_instance.xcom_pull('create_emr_cluster', key='return_value') }}",
step_id="{{ task_instance.xcom_pull('add_steps', key='return_value')[0] }}",
aws_conn_id='aws_default',
dag=dag
)
step_checker2 = EmrStepSensor(
task_id='watch_step2',
job_flow_id="{{ task_instance.xcom_pull('create_emr_cluster', key='return_value') }}",
step_id="{{ task_instance.xcom_pull('add_steps', key='return_value')[1] }}",
aws_conn_id='aws_default',
dag=dag
)
# 작업 실행이 완료된 후 DAG는 EMR 클러스터 종료 작업을 실행합니다.
cluster_remover = EmrTerminateJobFlowOperator(
task_id='remove_cluster',
job_flow_id="{{ task_instance.xcom_pull('create_emr_cluster', key='return_value') }}",
aws_conn_id='aws_default',
dag=dag
)
######################## Redshift #####################
# 먼저 Redshift IAM 서비스 역할 ARN을 가져오겠습니다.
# IAM 콘솔 - 역할 로이동
# AmazonMWAA-workshop-redshift-role을 검색하고 역할 이름을 클릭한 다음 역할 ARN을 복사합니다
copy_agg_to_redshift = CopyS3ToRedshiftOperator(
task_id='copy_to_redshift',
schema='nyc',
table='green',
s3_bucket=S3_BUCKET_NAME,
s3_key='data/aggregated',
iam_role_arn='arn\:aws\:iam::1111111111111\:role/AmazonMWAA-workshop-redshift-role', # 역할 붙여넣기
copy_options=["FORMAT AS PARQUET"],
dag=dag,
)
# DAG의 task들 실행
s3_sensor >> glue_crawler >> glue_task >> cluster_creator >> step_adder >> step_checker1 >> step_checker2 >> cluster_remover >> copy_agg_to_redshiftMWAA 실행
WEB UI 접속. 스케줄러에서 선택할 DAG( 켜기/끄기 토글 버튼 전환)를 활성화해야 합니다 . DAG가 활성화되면 DAG를 수동으로 실행할 수도 있습니다.

UI에서 트리거 버튼을 클릭하기만 하면 DAG가 실행됩니다.

Airflow DAG는 이제 파일이 s3://airflow-yourname-bucket/data/raw/green/ 경로의 S3에 도착할 때까지 기다립니다 .
DAG 실행을 시작하려면 Cloud9 콘솔에서 AWS S3 Cli 명령을 사용하여 데이터 파일을 지정된 경로로 복사합니다.
S3에 파일을 업로드하면 sensor가 감지하여 DAG를 실행한다
파일이 폴더에 복사되면 s3_sensor 작업이 완료로 이동하고 실행이 DAG의 다음 작업 세트로 전달됩니다.
(CLI 버전)
aws s3 cp s3://ee-assets-prod-us-east-1/modules/f8fe356a07604a12bec0b5582be38aed/v1/data/green_tripdata_2020-06.csv s3://airflow-yourname-bucket/data/raw/green/
실행 결과
성공적으로 완료되면 아래와 같이 녹색으로 표시된 모든 작업이 표시됩니다.
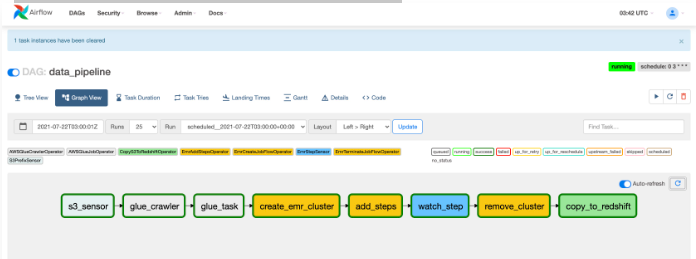
Glue가 파케이로 데이터를 저장

EMR이 aggregation한 데이터를 저장

aggregation된 파케이 파일을 Redshift로 로딩을 한다. 이데이터를 분석가들이 분석함


CloudWatch로 MWAA 컴포넌트 별로 로그 모니터링

에어플로우 UI에서도 로그들을 확인 가능함

CloudWatch 모니터링 시각화 대시보드

Step Functions : 적은 비용의 장점. 실시간 스트리밍(이벤트) 처리에 유용
MWAA : 배치 처리

MWAA의 단점

AWS Step Functions란 에어플로우에서 하는 일을 어느정도 대체해준다
Lambda를 실행하는 형태이기 때문에 서버를 관리하거나 중간에 실패하는 것에 대해 AWS가 로깅해주고 모니터링해준다
설정형태로 파이프라인을 관리할 수 있다

Athena를 트리거하는 EventBridge로 시작


왼쪽은 이벤트 브릿지 : 트리거되는 Input값을 정의.
오른쪽은 stepfunction : 모든 state의 리소스는 하나의 Lambda에서 다 처리되도록 이루어져있다
타입을 QeuryAthena라고 정의했다. Input이벤트를 마지막 함수까지 리턴하면서 타입으로 라우팅하는 방식. 마지막에 호출되는 Input의 타입이 wirte S3이다.

파이프라인 핸들러 코드(Lambda)
하나의 람다를 정의
다양한 함수를 이벤트의 type만 보고 라우팅한다. 해당함수를 실행한 리턴값이 핸들러의 리턴값으로 들어간다
StepFunction은 리턴된 이벤트의 밸류를 다음 함수의 Input값으로 사용할 수 있다
QueryAthena가 성공적으로 맞춰졌다면 CheckQueryFinished라는 함수를 계속 호출한다
def handler(ctx, e):
if err := e.validate(); err is not None:
# Handle validation error
pass
# Routing functions
if e["Type"] == "QueryAthena":
return query_athena(ctx, e)
elif e["Type"] == "CheckQueryFinished":
return check_query_finished(ctx, e)
elif e["Type"] == "WriteS3":
return write_s3(ctx, e)
return e, Exception("unsupported type")
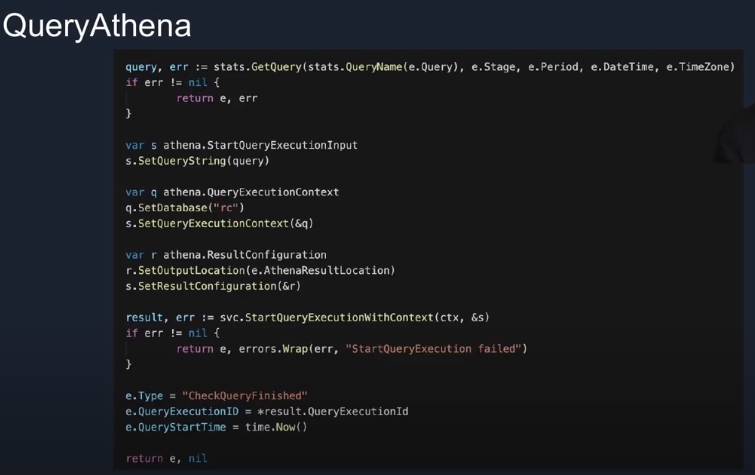
QueryAthena 코드(Lambda)
통계를 위한 쿼리를 별도로 관리하고 이를 수행만 하는 로직
StartQueryExecutionInput : 이벤트에 쿼리 start time을 심어준다. 일정 시간이 지나면 타임아웃을 주기 위함
QueryExecutionContext : 다음 로직에서 해당 쿼리가 끝났는지 체크하기 위함
import time
import boto3
def handler(ctx, e):
query, err = stats.GetQuery(stats.QueryName(e['Query']), e['Stage'], e['Period'], e['DateTime'], e['TimeZone'])
if err is not None:
return e, err
s = athena.StartQueryExecutionInput()
s.SetQueryString(query)
q = athena.QueryExecutionContext()
q.SetDatabase("rc")
s.SetQueryExecutionContext(q)
r = athena.ResultConfiguration()
r.SetOutputLocation(e['AthenaResultLocation'])
s.SetResultConfiguration(r)
result, err = svc.StartQueryExecutionWithContext(ctx, s)
if err is not None:
return e, Exception("StartQueryExecution failed")
e['Type'] = "CheckQueryFinished"
e['QueryExecutionID'] = result['QueryExecutionId']
e['QueryStartTime'] = time.time()
return e, None
- import time 및 import boto3: time 모듈과 boto3 모듈을 임포트하고 있습니다.
- def handler(ctx, e): handler 함수는 두 개의 인자 ctx와 e를 받습니다. ctx는 AWS Lambda 함수의 컨텍스트를 나타내며, e는 이벤트 데이터를 나타냅니다.
- query, err = stats.GetQuery(...): stats.GetQuery(...) 함수를 호출하여 query와 err 값을 얻습니다. GetQuery 함수는 주어진 입력 값에 따라 Athena 쿼리를 생성하는 작업을 수행합니다.
- if err is not None: return e, err: err이 None이 아닌 경우, 오류가 발생한 것이므로 e와 함께 해당 오류를 반환하고 함수를 종료합니다.
- s = athena.StartQueryExecutionInput(), q = athena.QueryExecutionContext(), r = athena.ResultConfiguration(): athena.StartQueryExecutionInput(), athena.QueryExecutionContext(), athena.ResultConfiguration()을 사용하여 쿼리 실행에 필요한 객체 s, q, r을 생성합니다.
- s.SetQueryString(query), q.SetDatabase("rc"), s.SetQueryExecutionContext(q), r.SetOutputLocation(e['AthenaResultLocation']): 각각의 객체에 필요한 값을 설정합니다. 예를 들어, s.SetQueryString(query)는 s 객체에 생성된 Athena 쿼리를 설정합니다.
- result, err = svc.StartQueryExecutionWithContext(ctx, s): svc.StartQueryExecutionWithContext(ctx, s)를 호출하여 Athena 쿼리 실행을 시작하고, 결과와 오류 값을 얻습니다.
- if err is not None: return e, Exception("StartQueryExecution failed"): err이 None이 아닌 경우, Athena 쿼리 실행에 실패한 것이므로 해당 오류를 반환하고 함수를 종료합니다.
- e['Type'] = "CheckQueryFinished", e['QueryExecutionID'] = result['QueryExecutionId'], e['QueryStartTime'] = time.time(): 이전 단계에서 생성된 result에서 쿼리 실행 ID를 가져와 e 객체의 필드에 설정합니다. 또한 e 객체의 Type 필드를 "CheckQueryFinished"로 설정하고, QueryStartTime 필드를 현재 시간으로 설정합니다.
- return e, None: e와 None을 반환하여 함수를 종료합니다.
위의 코드는 주어진 이벤트 데이터를 기반으로 Athena 쿼리를 실행하고 결과를 처리하는 작업을 수행하는 AWS Lambda 핸들러 함수입니다.
Write S3 코드(Lambda)
import boto3
import io
import csv
import datetime
def handler(ctx, e):
ip = atena.GetQueryResultInput()
ip.SetQueryExecutionId(e['QueryExecutionID'])
op, err = athenaSVC.GetQueryResultsWithContext(ctx, ip)
if err is not None:
return e, Exception("GetQueryResults failed")
resultCSV = io.StringIO()
writer = csv.writer(resultCSV)
for row in op['ResultSet']['Rows']:
dataLen = len(row['Data'])
csvRow = []
for i, data in enumerate(row['Data']):
if 'VarCharValue' not in data:
return e, None
csvRow.append(data['VarCharValue'])
if dataLen != (i + 1):
csvRow.append(",")
writer.writerow(csvRow)
resultCSVStr = resultCSV.getvalue()
key = f"/{e['Stage']}/stats/query={e['Query']}/period={e['Period']}/year={e['DateTime'][:4]}/month={e['DateTime'][5:7]}/{e['DateTime']}.csv"
try:
response = s3svc.put_object(
Bucket=e['StatsBucket'],
Key=key,
ContentLength=len(resultCSVStr),
Body=resultCSVStr
)
except Exception as err:
return e, Exception("PutObject failed")
return e, None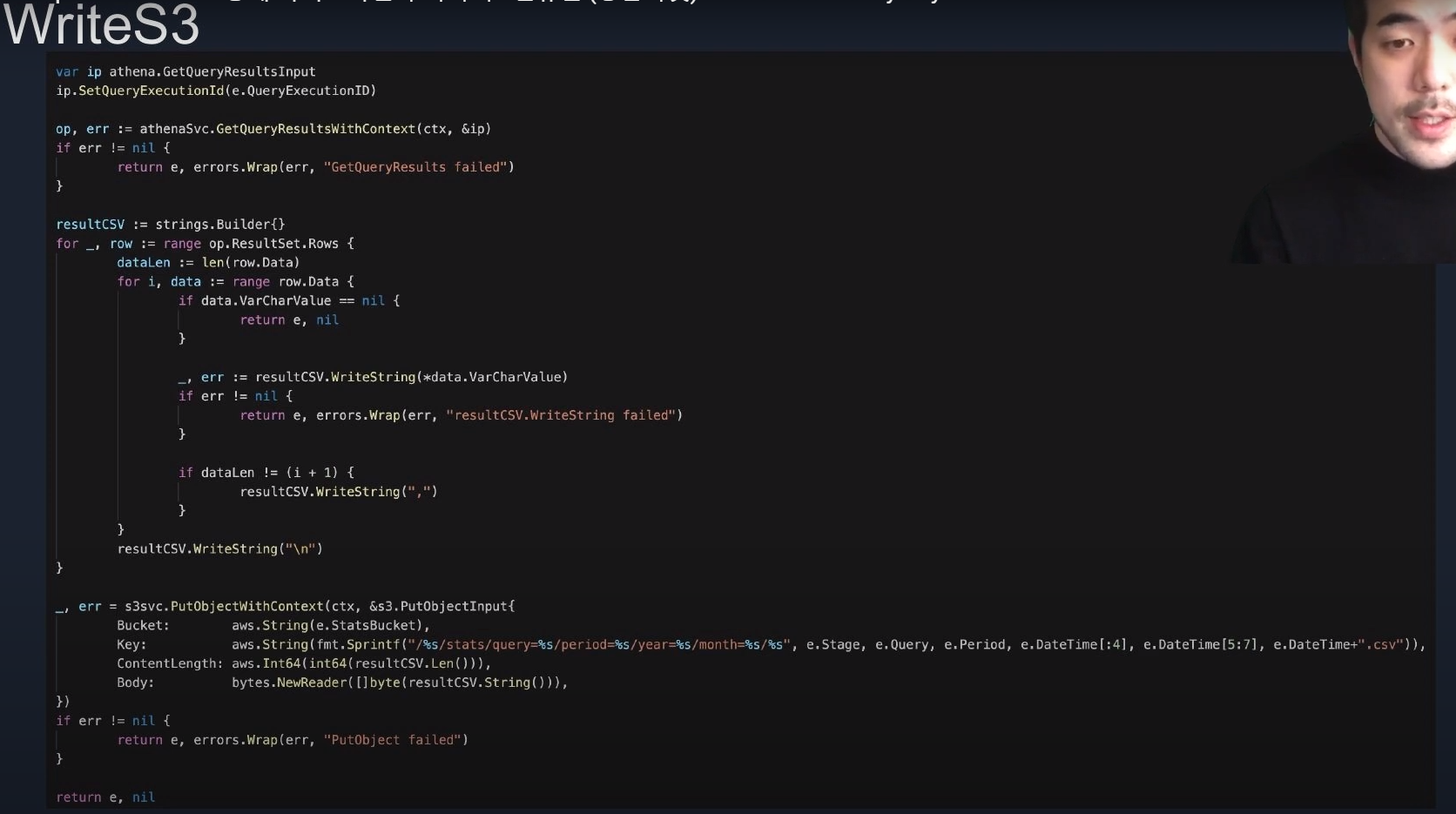
쿼리 네임만 바꾸고 스케줄러만 추가하면 S3로그가 되어있고 S3로 쿼리
원하는 지표가 있으면 로직에 쿼리를 추가하고 스케줄 추가하고 인풋값만 수정하면 된다

StepFunction 코드
{
"Comment": "Query for statistics",
"StartAt": "QueryAthena",
"States": {
"QueryAthena": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-2:606203148720:function:QueryAthena",
"Next": "WaitQuery"
},
"WaitQuery": {
"Type": "Wait",
"Seconds": 10,
"Next": "CheckQueryFinished"
},
"CheckQueryFinished": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-2:606203148720:function:main",
"Next": "CheckQueryState"
},
"CheckQueryState": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.query_state",
"StringEquals": "FAILED",
"Next": "DefaultState"
},
{
"Variable": "$.query_state",
"StringEquals": "CANCELLED",
"Next": "DefaultState"
},
{
"Variable": "$.query_state",
"StringEquals": "QUEUED",
"Next": "WaitQuery"
},
{
"Variable": "$.query_state",
"StringEquals": "SUCCEEDED",
"Next": "WriteS3"
}
],
"Default": "DefaultState"
},
"DefaultState": {
"Type": "Fail",
"Cause": "No Matches!"
},
"WriteS3": {
"Type": "Task",
"Resource": "arn:aws:lambda:ap-northeast-2:606203148720:function:WriteS3",
"End": true
}
}
}
다른 Lambda를 호출하게 되면 AWS X-Ray를 on해서 손쉽게 볼 수 있다

댓글